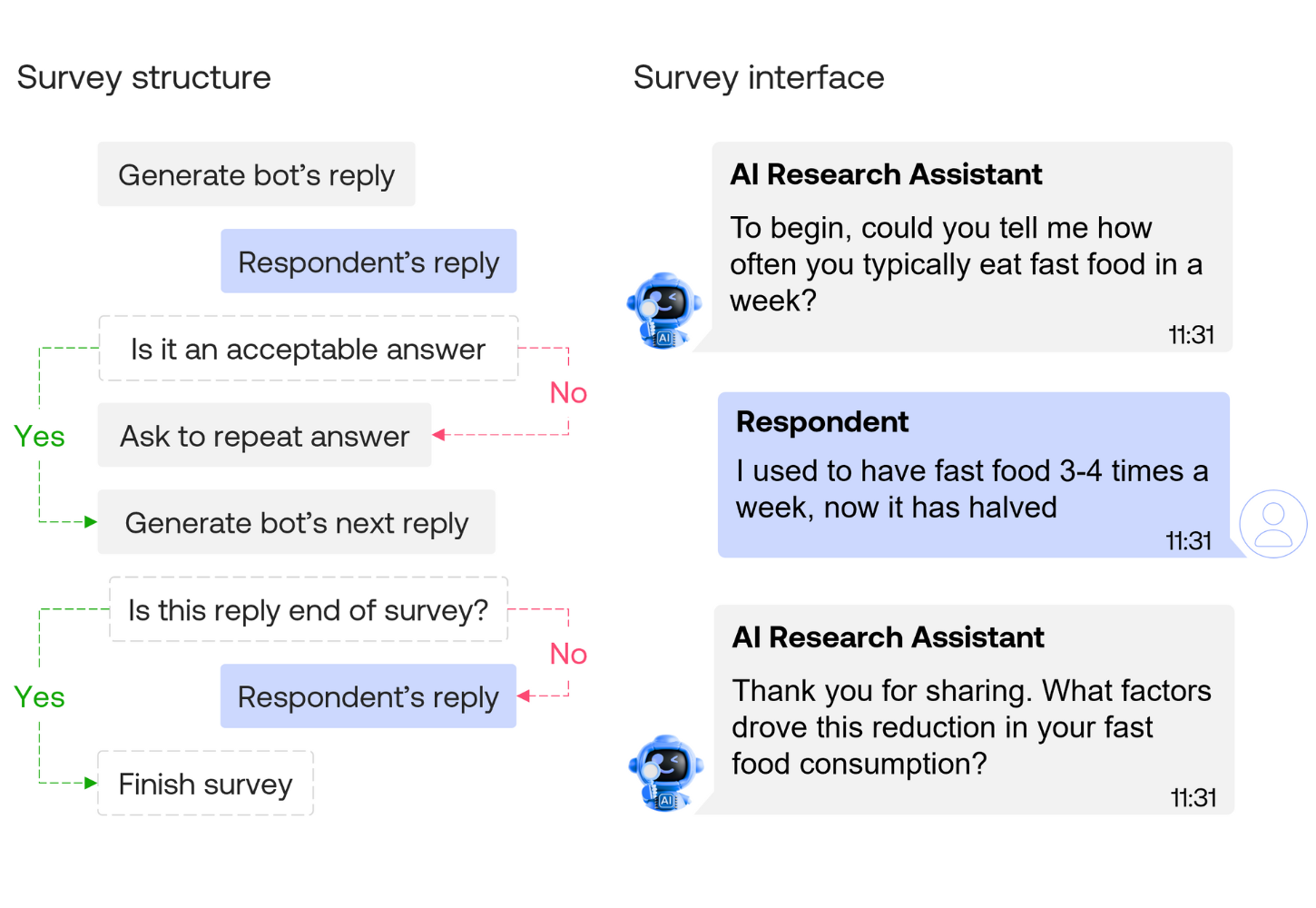
This article covers how synthetic responses are generated, their unreliability and invalidity, the allure of synthetic respondents, and the effects of this trend.
Every industry or field of knowledge has its own faux alter-ego. Astronomy has astrology. Medicine and homoeopathy. The time has finally come for market research to have its own. Its name is synthetic respondents.
It is of course a misnomer. Unlike respondents (i.e. people), synthetic respondents are answers generated by large language models. A cottage industry of sellers of survey-like AI-generated data has emerged and is trying to take hold within the market research industry. They are invited to conferences and being legitimised by industry gurus. Worse still, several academic research papers make it sound like a legitimate research method, overplaying its applicability.
In this article, I cover how these fake responses are generated, their reliability and validity. Then I examine the allure of synthetic respondents. And finally, discuss the effects of this trend.
How do synthetic respondents work
From the research user perspective, reports generated using fake responses have the same shape and form as reports based on real data. They are typically structured around survey questions. They purport to have a certain number of responses. The same types of analysis like tabulation, correlation, multidimensional scaling, and so on can be performed on them.
A few months ago some fake data sellers shied away from labelling their offering “synthetic”. You could easily mistake them for actual market research providers. Now they prefer to use obscure flowery language like “augmented audiences”. It’s an improvement of course, but not distinguishable enough for novice research buyers.
Generating responses from LLMs takes a fair bit of preparation (i.e. building out a platform that does that) but then only a few minutes per each new report. Typically fake data merchants will use prompts like this (example prompting of GPT 3.5):

Pre-prompt: You are a 45 year old mother of three children. You eat bread for breakfast, you eat spaghetti for lunch and you like to vary your meals for dinner. Your budget for everything is limited because you are on government allowance. Next please answer several questions asked of you. In giving answers you will strictly follow the required format and will not add any additional words. Prompt: How many loaves of bread do you buy per week? (Response format: Numeric) LLM completion: 2 Prompt: What types of bread do you normally buy? 1. White bread 2. Wholemeal bread 3. Rye bread 4. Other type of bread (Response format: Integer corresponding to the selected option)
LLM completion: 1 Prompt: Describe the taste of the bread that you like the most. (Response format: Open-ended text response up to 255 characters)LLM completion: Soft, fluffy, and slightly sweet, with a light crust.
This process is repeated multiple times with slight variations of the pre-prompt to match different demographic segments. Various other information about the “respondent” is inserted there.
Fine-tuning of models. Some companies claim to “train” (by which they typically mean “fine-tune”) large language models based on people’s answers to past surveys. Thus, they either:
Create a version of an LLM (such as Llama) for each personality that they pretend to represent (which would be quite expensive and I doubt they actually would do that), or
Create a single fine-tuned LLM instance that mashes together different respondent demographics and personalities (which is a legal risk to them because if they should receive a “right to be forgotten” request they would need to delete the whole model).
In fairness, both options are also a legal risk because it is not likely the original respondents consented to such processing of their responses.
Why are they bothering with individual response generation, when they can just use AI to generate the final report? The main reason is to provide internal consistency of the results. If you want to have count analysis on fake responses, you can. If you want correlations, you can. If you want any other types of analysis, you can too.
We’ve all been trained at school to think that internal consistency is a marker of the quality of intellectual labour. Fake response generation exploits that view.
A demonstration of test-retest unreliability of fake responses
Let’s do a demonstration and have GPT 4, not fine-tuned on any particular answers, complete a short questionnaire:
- What is your annual household income? (Insert only USD numerical integer values)
- What do you have for breakfast? (Open-ended response)
- What type of toilet paper do you prefer the most? (Choose strictly one option)
- Soft bleached
- Standard bleached
- Soft non-bleached
- Standard non-bleached
Now, let’s create a pre-prompt template:
You are _ years old male/female. You live in the state of _. You come from a low/middle/high-class family. You have [no] children. Please answer the following questions just like a survey respondent would. In giving answers you will strictly follow the required format and will not add any additional words.
And let’s repeat the exercise with a slightly different pre-prompt template that contains the same information:
As a _-year-old man/woman from a low/middle/high-class family in _ with [no] children, respond to these survey questions. You must strictly follow the required format, adding no extra words.
Let’s compare the results:
| Attempt 1 | Attempt 2 | Significant difference at a 95% level (two-sided) | |
|---|---|---|---|
| Mean household income | $111,348 | $272,014 | Sig. different |
| Median household income | $50,000 | $70,500 | Sig. different |
| Proportion of people who have coffee for breakfast | 81% | 67% | Sig. different |
| Proportion of people who have oatmeal for breakfast | 55% | 29% | Sig. different |
| Proportion of those who prefer soft bleached toilet paper | 92% | 66% | Sig. different |
| Proportion of those who prefer standard bleached toilet paper | 8% | 33% | Sig. different |
| Proportion of those who prefer soft non-bleached toilet paper | 0% | 1% | - |
| Proportion of those who prefer standard non-bleached toilet paper | 0% | 0% | - |
| Number of attempts | 300 | 300 |
I varied the wording of the pre-prompt (and should note that the randomness parameter was set at 1, which is pretty common and indeed needed to generate different responses for the same demographics), and got completely different results.
To reiterate, the information in the pre-prompt was not different. Just how it was worded massively affected the results. This is a demonstration of the test-retest unreliability of using LLM-generated responses.
Sources of error when using fake respondents
Every research method has sources of error. For survey research, one may list things like sampling error; measurement error; coverage error; non-response error. Here are some of the more peculiar types of errors for fake respondents:
- Training data error (i.e. what texts was the LLM trained on?)
- Training method error (i.e. what algorithm of training was used?)
- RLHF error (i.e. what human feedback was used to adjust the model after the pre-training stage? How?)
- Prompting error (i.e. what prompt was used?)
- Inference parameter error (i.e. what penalties and temperature were set at the inference stage?)
These are plenty of sources of error that are not only novel for most users of survey research, but also incomprehensible because, for example, we do not know what training data was used for GPT-4 or almost any other proprietary model. Same goes for the training and RLHF methods.
Most of the above sources of error would be eliminated if one used real online customer reviews. It’s the same textual format as LLM completions, but without the unnecessary processing and introduction of unpredictable errors during it.
External invalidity of LLM completions
Mark Ritson recently celebrated synthetic data by declaring that “the era of synthetic data is clearly upon us.” [1] He linked a 2022 study about generating perceptual maps from synthetic data that showed remarkably similar results from synthetic data and real respondents [2] for different car brands:

Figure 1 from Peiya Li et al.: Perceptual maps using overall similarity score and EvoMap (t-SNE). GPTNeo and GPT4 are AI-generated synthetic data, while the Human Open and Human Rating are two different survey datasets from real people.
The authors also repeated their analysis on popular apparel brands and reported similarly strong agreement between human respondents and LLM-generated texts.
Why do we see this? Because the training datasets for both GPTNeo and GPT-series models probably contain Americans’ ratings of these popular car and apparel brands. It is not possible to verify this in the case of proprietary OpenAI models because datasheets are kept secret (if they even exist). And it is no longer possible to search the original Pile [3] (the original dataset used to train GPTNeo) because it has been taken down due to copyright violations in at least one of its parts called Books3 [4]. But is it entirely plausible that some of the Arxiv articles used to train GPTNeo contained the scoring data related to the car and apparel brands.
The authors themselves acknowledge this as a limitation:
“Since we use pre-trained language models, we are limited by the data set that was used to train said language models. The trend is to use increasingly large and broad training data inclusive of information relevant to all aspects of life, hence we should expect relevant market information. Nonetheless, we cannot guarantee the presence of relevant data in the training set unless we use our own data to enhance and retrain the models.”
What happens if you prompt any commonly used LLM to generate data for a perceptual map outside of its training distribution, say for tea brands in South Korea in 2023? My prediction is that it will produce garbage [5].
It’s worth noting that because you do not know what most of the LLMs were trained on, you do not know what kind of knowledge they encode. Therefore you do not know when the topic of your research is in the training dataset and when it is not. Simply this one observation is enough to make anyone interested in getting real data look the other way from synthetic respondents.
In our attempt to replicate the analysis from Language Models for Automated Market Research: A New Way to Generate Perceptual Maps" by Peiyao Li et al., we found mixed evidence on the potential for using synthetic LLM-generated data in market research applications like perceptual mapping.
In cases very close to training data distributions, like geography-driven rugby team perceptions, the synthetic data correlated reasonably well compared to human surveys.
However, replicating perception maps where there is not a simple heuristic to latch on to appears to be a more difficult task. LLM generated data struggled to capture nuanced associations made by real consumers in less represented domains like Australian café chains. Please see the below perceptual maps and try to guess which one is real:
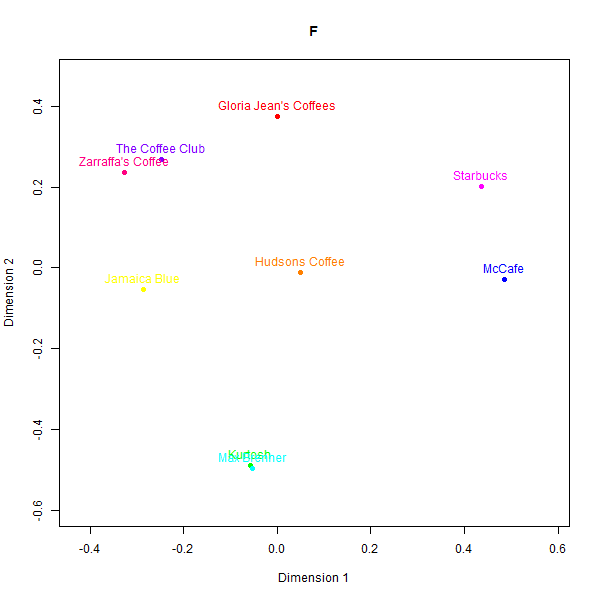
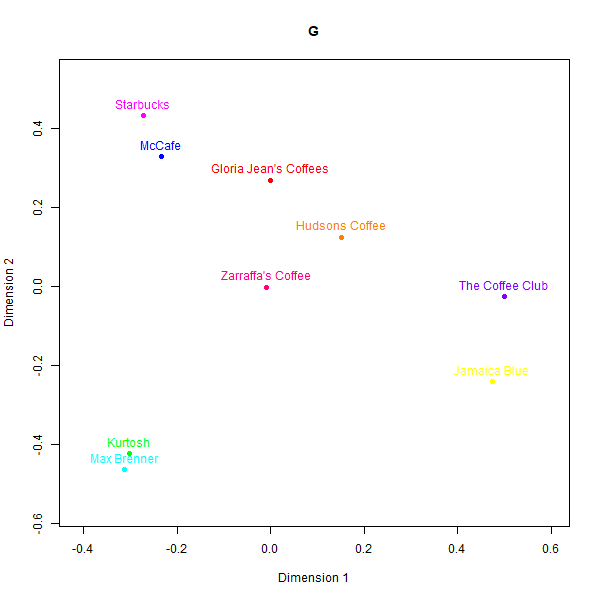
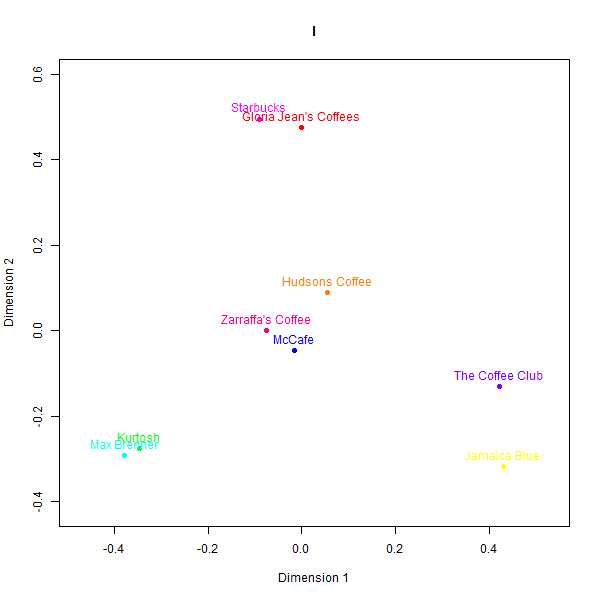
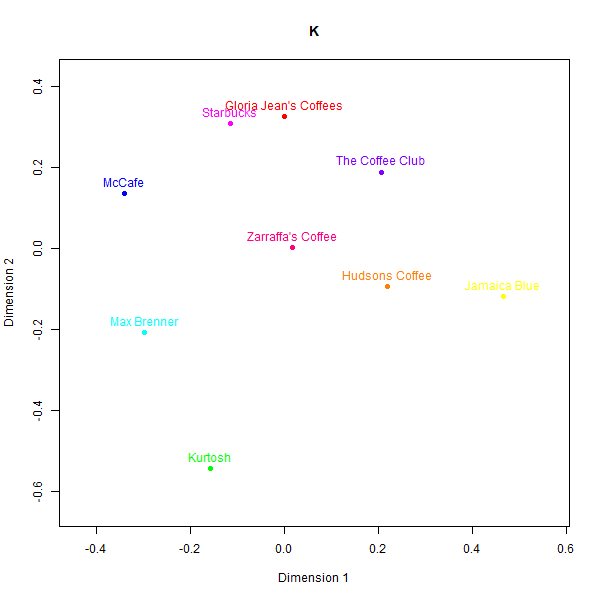
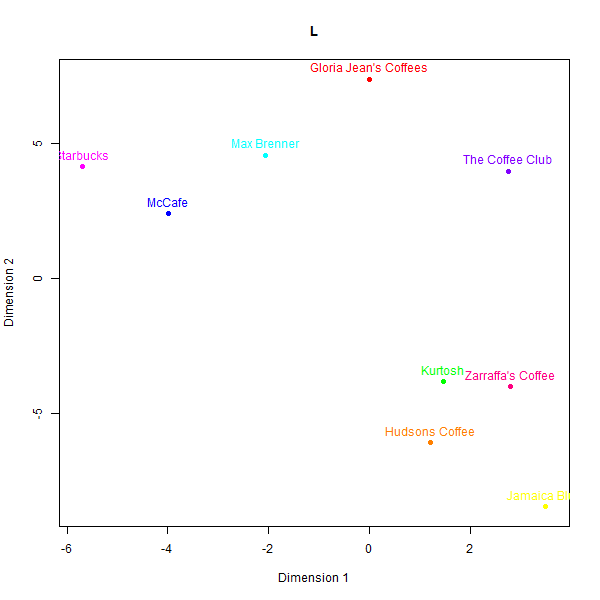
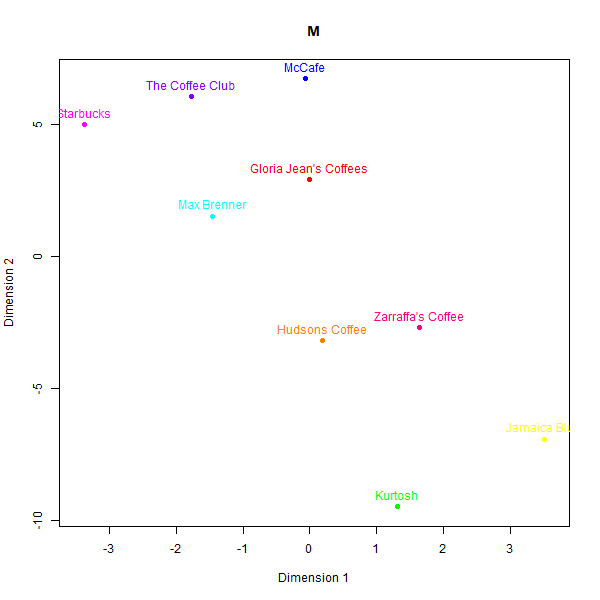
This is what the labels mean:
- F: GPT-3.5-Turbo
- G: GPT-4
- I: GPT-4-Turbo
- K: Real data
- L: Judgement from the first team member
- M: Judgement from the second team member
While some basic clusters are preserved, such as separating out high-end cafés from fast food chains, the relative positioning of brands and inter-brand distances show substantial dissimilarity versus the human survey benchmarks.
In addition, LLM providers do not provide enough information about the data used to train their models. This makes it difficult to know if a model will work well for a specific market research context. Also, we observed different models from the same company can give very different results. So, even if one wants to use fake data from an LLM, it is tricky to choose the right model for the job.
Invalidity of sampling frame
The most important reason why we cannot use LLMs for research is that we do not trust LLMs to make purchase decisions for us as consumers. If we did, then we should be able to survey LLMs instead of people.
Consider wanting to know what baby food mothers want for their children. Normally, you go and survey mothers for that. You do not survey grandmothers with the question, “What do you think young mothers would want for their babies?”
Grandmothers might actually have a good idea of what today’s mothers want for their babies. Yet it’s all too easy to see why the broken telephone effect would make research findings unreliable and largely unusable (unless grandmothers are your true target market).
Similarly with LLMs, unless you can trust an LLM to actually go out and make purchases like a real customer, you should not trust it to accurately tell you about customer behaviour and purchase drivers.
The allure of synthetic respondents
The allure of synthetic respondents comes from several factors:
- faster execution,
- the promise of lower costs,
- the promise to reach hard to get audiences,
- the ability to ask questions that would be difficult to pose to real people.
All of the above are indeed true in the same sense they are true of séances as a market research method. What’s also true both for synthetic audiences and séances is that they do not provide reliable answers to business questions.
Playing hard make-believe
And the LLM responses themselves are optimised to exploit gullibility because they are meant to produce human-like text. There are two processes in training LLMs that help achieve that.
Pre-training. This is an unsupervised learning step (unsupervised in the sense that there is no human who gives a model “sticks” or “carrots”), in which the systems ingest a lot of scraped data (including copyrighted texts — without authors’ consent, credit, or compensation in violation of laws and principles of decency). The model learns to mimic human text, which already has many sentences like “Burgers are tasty”, “Charity is good”. So even after this step if you could prompt the model with “Burgers are " and it would likely auto-complete to “tasty”.
Reinforcement learning from human feedback. This is a somewhat complicated step, but it relies on a quite basic activity. A large group of people (often underpaid in Africa where labour laws are not strong) sit in front of a computer all day and are exposed to various completions from the first step. Their job is to press 👎 or 👍. Based on such “sticks” or “carrots”, the model is moulded into something that even better represents human answers, not necessarily truthful answers, often sycophantic ones instead [6].
So when someone makes an observation that there are correlations between an average human answer and an LLM completion, it is not at all surprising, interesting, or note-worthy. That’s what LLMs are designed to do.
On top of that, the economics of a synthetic data provider is quite favourable compared to a market research firm. They do not have to spend money on sample, the hard labour of the fieldwork team who check response quality, and they can also churn projects quicker (meaning greater cash flow velocity that frees up operating capital). That means they have more money left on sales. Therefore expect snake oil merchants to deliver very slick presentations.
When can you actually use synthetic data?
Since you cannot use LLMs for real business questions, is synthetic data useful for anything at all? Yes:
- Testing questionnaires. In this case, it should be called “questionnaire testing using LLM-generated responses” (not “market research”) and you would need to write a scrappy JavaScript at the cost of a few hundred dollars, not hire a platform company to do it.
- Early-stage idea generation. In this case, again, no need for a synthetic data company at all. Anyone will do just fine with Chat-GPT.
- When you need a placebo effect from a project, and do not care about the answers.
The last case is very interesting. I’ve seen more than one research or consulting project that was done for the sake of having a project. The management may be completely disinterested in the outputs but for whatever reason still assigns a team to do something. In this case indeed it is anyone’s preference on where to waste money and fake data is a clear alternative. Another option is tasseography, also known as Turkish coffee fortune telling:

You can organise a fun team activity around it. You may even spend the budget on going to Türkiye for an authentic high-quality experience.
Seriously though, if you are doing a placebo project and do not want to do surveys, consider doing secondary or tertiary research instead. Read what others have written about your topic. If you like talking to people, get UserInterviews a go. Or use the research budget to hire a university student on freelancer.com to do the research for you.
Please do not feed the fake data cottage industry.
Where does the fake data trend take us?
The uncritical reception of fake data companies in the industry press exposed an uncomfortable truth about the research industry: Intermediaries will take money from just about anyone who wants a share of research buyers’ budget. Should you even listen to their webinars after this scandal?
As for companies who proudly supply fake responses and declare that to be the future of market research? I suspect they will continue to exist. A business model based on lies should not be sustainable, but at the same time homoeopathy still exists.
Caveat emptor.
Appendix 1: Code for a demonstration of test-retest unreliability of fake respondents
openAIkey <- "..."
#### Load the libraries ####
library(httr)
library(jsonlite)
#### Define functions ####
requestChatCompletion <- function(messages) {
body <- list(
model = "gpt-4",
messages = messages,
temperature = 1,
max_tokens = 500,
top_p = 1,
frequency_penalty = 0,
presence_penalty = 0
)
r <- POST('https://api.openai.com/v1/chat/completions',
body = toJSON(body, auto_unbox = TRUE),
httr::add_headers(Authorization = paste("Bearer", openAIkey)),
httr::content_type('application/json'))
response = content(r)
return(response)
}
getAnswers <- function(preprompt, questions) {
completions <- c()
messages <- list(
list(
role = "system",
content = preprompt
)
)
for (i in seq_along(questions)) {
messages <- append(messages, list(
list(
role = "user",
content = questions[i]
)
))
completions <- append(completions, requestChatCompletion(messages = messages)$choices[[1]]$message$content)
messages <- append(messages, list(
list(
role = "assistant",
content = completions[i]
)
))
}
return(completions)
}
#### Test execution ####
preprompt1 <- "You are 35 years old male. You live in the state of Washington. You come from a low-class family. You have children. Please answer the following questions just like a survey respondent would. In giving answers you will strictly follow the required format and will not add any additional words."
questions <- c(
'What is your annual household income? (Insert only USD numerical integer values)',
'What do you have for breakfast? (Open-ended response)',
'What type of toilet paper do you prefer the most? (Choose strictly one option denoting only its number)\n1. Soft bleached\n2. Standard bleached\n3. Soft non-bleached\n4. Standard non-bleached'
)
getAnswers(preprompt1, questions)
# Example output here: c("25000", "Cereal and coffee.", "1")
#### Generate demographic data ####
N <- 300
age <- round(runif(N, 18, 67),0)
gender <- sample(c("male", "female"), N, replace = TRUE)
state <- sample(c("Oregon", "Washington", "California"), N, replace = TRUE)
stratum <- sample(c("low", "middle", "high"), N, replace = TRUE)
children <- sample(c("", "no "), N, replace = TRUE)
sex <- gender
sex[sex == 'male'] <- 'man'
sex[sex == 'female'] <- 'woman'
prepromptTemplate <- "You are %s years old %s. You live in the state of %s. You come from a %s-class family. You have %schildren. Please answer the following questions just like a survey respondent would. In giving answers you will strictly follow the required format and will not add any additional words."
preprompts <- sprintf(prepromptTemplate, age, gender, state, stratum, children)
#### Generate completions ####
allCompletions <- list()
pb <- txtProgressBar(min = 0, max = length(preprompts), style = 3)
for (i in seq_along(preprompts)) {
Sys.sleep(1) # Sleep for 1 second to avoid OpenAI API rate limit
setTxtProgressBar(pb, i)
allCompletions[[i]] <- getAnswers(preprompts[i], questions)
}
allCompletions <- do.call(rbind, allCompletions)
allCompletions <- as.data.frame(allCompletions)
colnames(allCompletions) = c("income", "breakfast", "toiletPaper")
write.csv(allCompletions, file = "allCompletions.csv", row.names = FALSE)
#### Analyse results ####
income <- as.numeric(allCompletions[, 1])
breakfast <- allCompletions[, 2]
toiletPaper <- as.numeric(allCompletions[, 3])
summary(income) # Distribution of annual household income
mean(grepl("coffee", breakfast, ignore.case = TRUE)) # Proportion of people who have coffee for breakfast
mean(grepl("oatmeal", breakfast, ignore.case = TRUE)) # Proportion of people who have oatmeal for breakfast
table(toiletPaper) # Distribution of toilet paper preferences
save.image(file = "fake-data-generation.RData")
#### Generate fake data. Attempt 2 ####
prepromptTemplate2 <- "As a %s-year-old %s from a %s-class family in %s with %schildren, respond to these survey questions. You must strictly follow the required format, adding no extra words."
preprompts2 <- sprintf(prepromptTemplate2, age, sex, stratum, state, children)
#### Generate completions ####
allCompletions2 <- list()
pb <- txtProgressBar(min = 0, max = length(preprompts2), style = 3)
for (i in seq_along(preprompts2)) {
Sys.sleep(1) # Sleep for 1 second to avoid OpenAI API rate limit
setTxtProgressBar(pb, i)
allCompletions2[[i]] <- getAnswers(preprompts2[i], questions)
}
allCompletions2 <- do.call(rbind, allCompletions2)
allCompletions2 <- as.data.frame(allCompletions2)
colnames(allCompletions2) = c("income", "breakfast", "toiletPaper")
write.csv(allCompletions2, file = "allCompletions2.csv", row.names = FALSE)
#### Analyse results ####
income2 <- as.numeric(allCompletions2[, 1])
breakfast2 <- allCompletions2[, 2]
toiletPaper2 <- as.numeric(allCompletions2[, 3])
summary(income2) # Distribution of annual household income
mean(grepl("coffee", breakfast2, ignore.case = TRUE)) # Proportion of people who have coffee for breakfast
mean(grepl("oatmeal", breakfast2, ignore.case = TRUE)) # Proportion of people who have oatmeal for breakfast
table(toiletPaper2) # Distribution of toilet paper preferences
save.image(file = "fake-data-generation2.RData")
Datasets generated in the code above:
It cost us around USD 13 to generate these datasets using the OpenAI API.
References
[1] Synthetic data suddenly makes very real ripple, Mark Ritson, Marketing Week, 2023.
[2] Language Models for Automated Market Research: A New Way to Generate Perceptual Maps, Peiyao Li et al., 2022. This has been published in Marketing Science.
[3] GitHub - EleutherAI/the-pile.
[5] I am hoping to replicate the study and try the methodology in a different context when the papers’ authors provide the code they used.
[6] [2310.13548] Towards Understanding Sycophancy in Language Models.