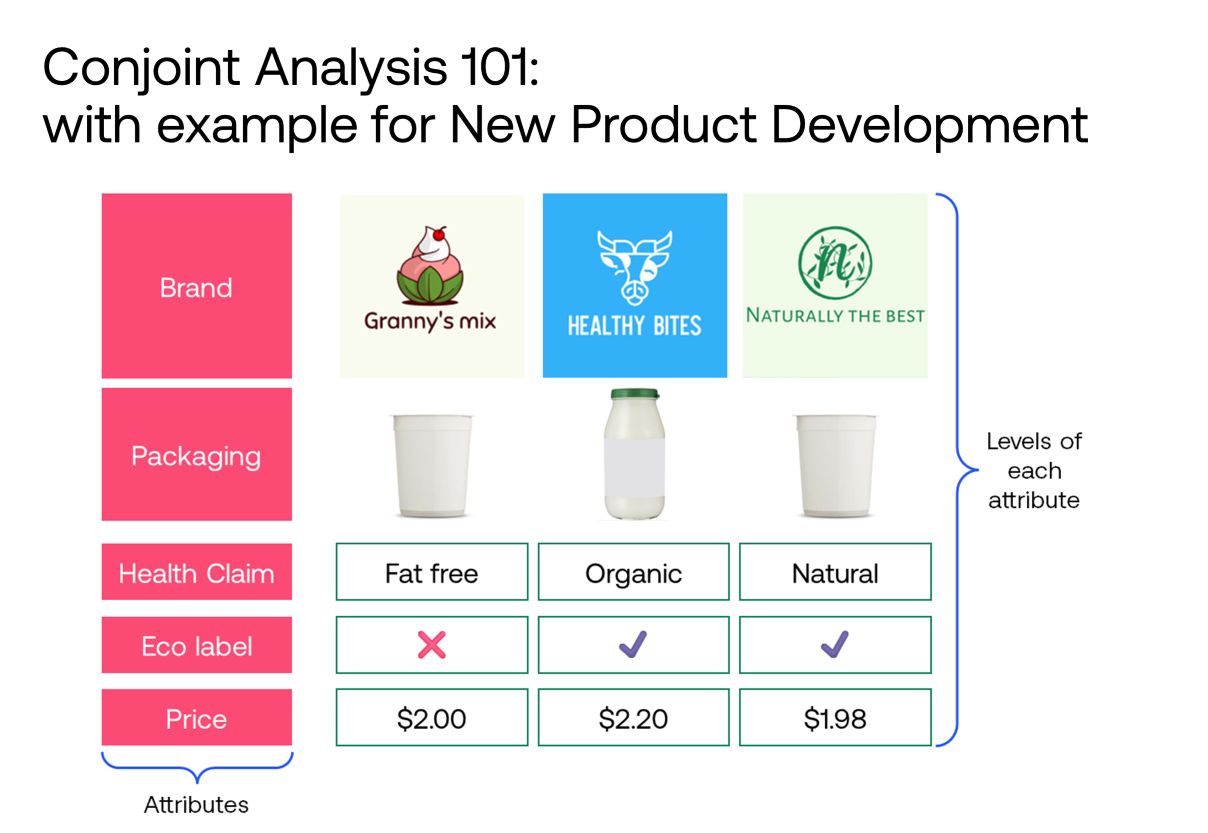
What are the different statistics available for a single variable? Selecting statistics for a single variable depends of the type of variable: nominal, ordinal, or interval.
OK, you have collected your data and want to learn more about a single variable in it. How can you do that? What kinds of statistical metrics (statistics) can you use?
The answer depends on the scale of measurement of that variable. The table below provides a summary of that:
| Type of variable | Central Tendency | Frequencies | Dispersion | Symmetry | Peakedness | Normality |
|---|---|---|---|---|---|---|
| Nominal | Mode | Relative frequencies (e.g. percentages) or absolute frequencies | The relative frequency of modal value | |||
| Ordinal | Median | Relative frequencies (e.g. percentages) or absolute frequencies, or N-tiles | Inter-quartile deviation | |||
| Interval | Mean , Median, and other measures (see below) | Relative frequencies (e.g. percentages) or absolute frequencies, or N-tiles | Standard deviation or coefficient of variation, or range | Skewness | Kurtosis | Kolmogorov-Smirnov one sample test or Lilliefors extension of the Kolmogorov-Smirnov test, or the Chi-square goodness of fit test |
Selecting an appropriate metric for central tendency of interval variables
This can be tricky. We suggest you should consider the following:
- Are there significant outliers (for which you may need to do a plot of the data)?
- Is the distribution skewed?
If there are outliers, we recommend doing one of the following transformations to your variable:
- Winsorizing the dataset
- Trimming it (i.e. removing extreme values)
If your distribution is not symmetric (i.e. is skewed), you should use both mean and median.
This post is based on A Guide for selecting statistical techniques for analyzing social science data.