
What is wrong with Kano model? We address five criticisms of Kano and show how to work through them.
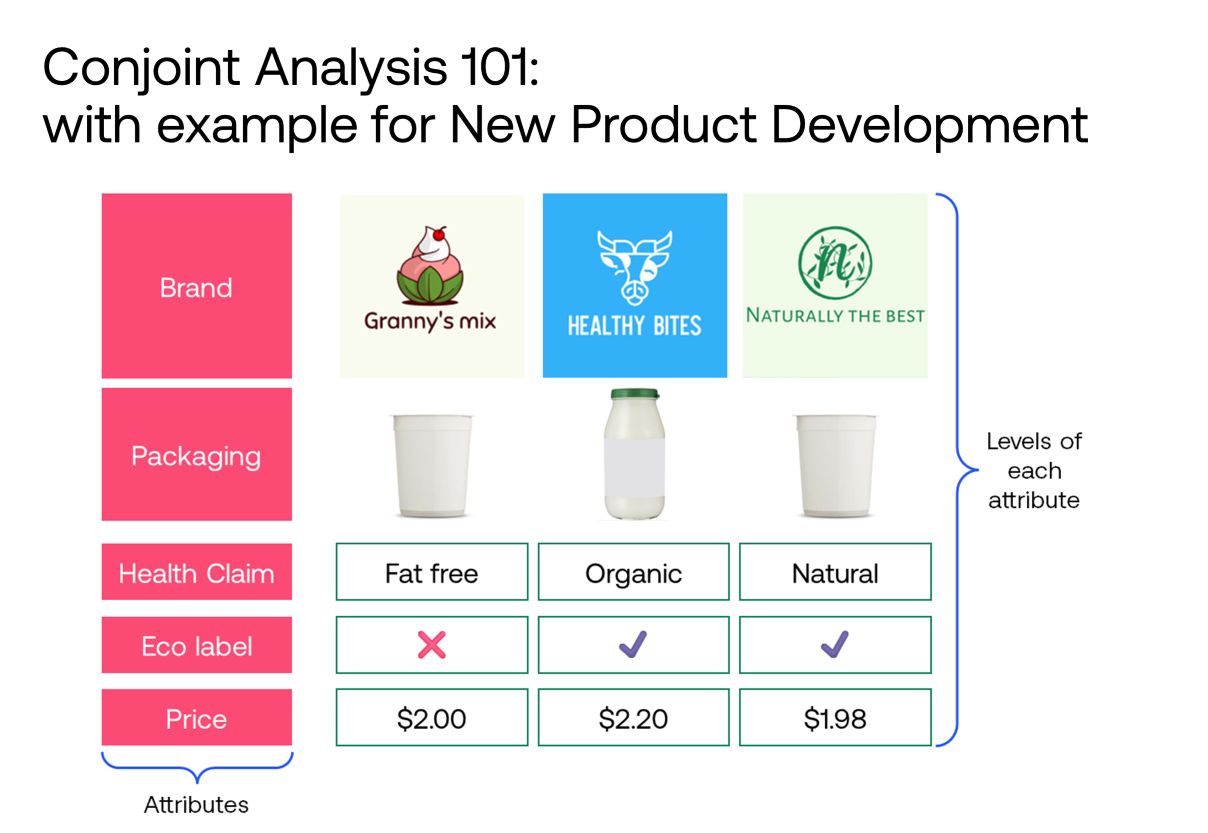
Kano Model
Ensure product-market fit and maximise your user acquisition and expansion, by differentiating software features according to your users' needs.
Powerful voices in the market research world, including Chris Chapman and Mario Callegaro recommend not to expect results from Kano studies to be replicable or correct. They list four criticisms of the Kano model:
- The theory is questionable: for tech products, Performance, Must-haves, and Attractive features are difficult to distinguish.
- Item wording and response scales are poor.
- The response scale is not unidimensional.
- For
N < 200, Kano category assignments are unstable.
Let’s dive into each one.
1. Theoretical criticism
There is a huge difference between Must-haves and Attractives. Must-haves are the things you must provide to users to keep them from looking for alternatives, or else basics are not satisfied by your product. Attractive features are the ones you can put your advertising and ask your salesforce to stress when they give demos to clients. Over time, as competition catches up, users’ expectations change and attractive features can become must-haves or performance features.
The classification of performance features is indeed a weaker theoretical spot of the Kano model. They sit between attractives and must-haves, and are a little hard to conceptualise in the context of software products. You should treat them as perhaps both must-haves and attractives.
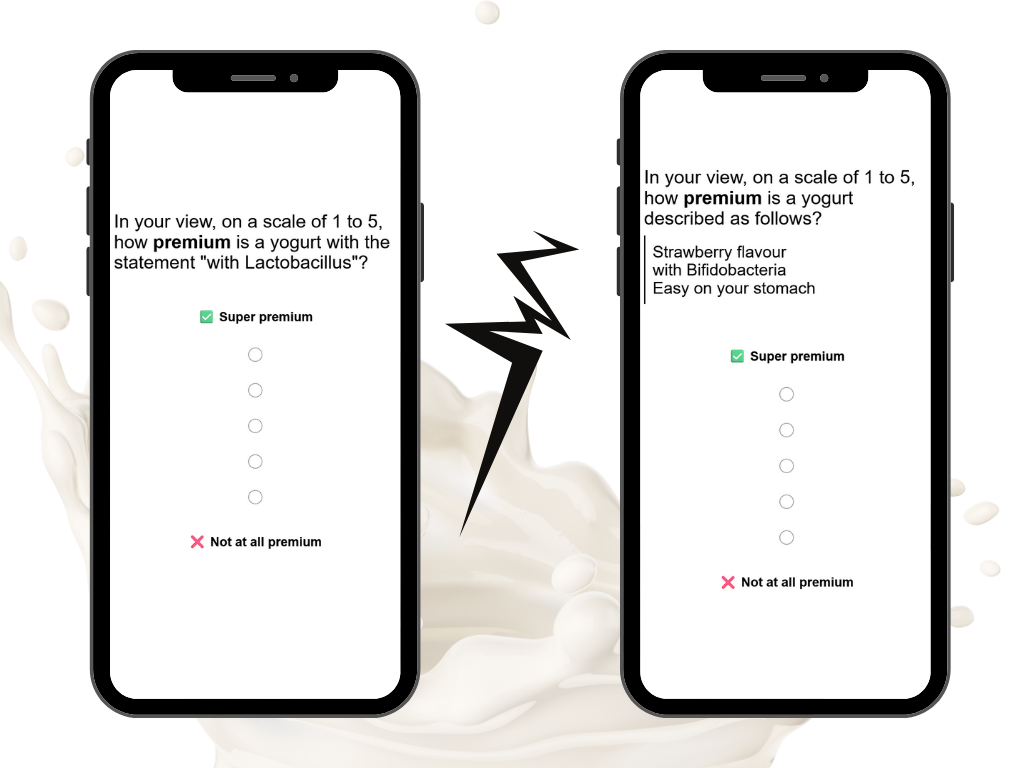
2. Poor item wording
Kano items:
are indeed not MECE (mutually exclusive, collectively exhaustive). For example, people can both expect and love a feature.
But that is OK. We are interested in people’s dominant attitude towards a feature. To be pedantic, one can reword the question:
How would you feel if the 4K HD video was included in this software?
into
Which of the following best describes how you would feel if the 4K HD video was included in this software?
But that is a pedantic lengthening of a question in pursuit of correctness, away from readability.
There is indeed a problem with how well people can understand the dysfunctional question. To aid understandability, we recommend always to ask the dysfunctional question after the functional question for each feature. That is the default on the Conjointly platform.
3. The response scale is not unidimensional
Yes, they are not. That is the whole point of running a Kano model study instead of a MaxDiff.
Thanks to having not MECE, not unidimensional items in the Kano model we can distinguish between Attractive features and Must-haves.
4. For small sample sizes, Kano category assignments are unstable
Indeed, because normally a “first past the pole” approach is applied to classification between category frequencies, Kano results can be unstable for small sample sizes. There are two tricks to alleviate this concern:
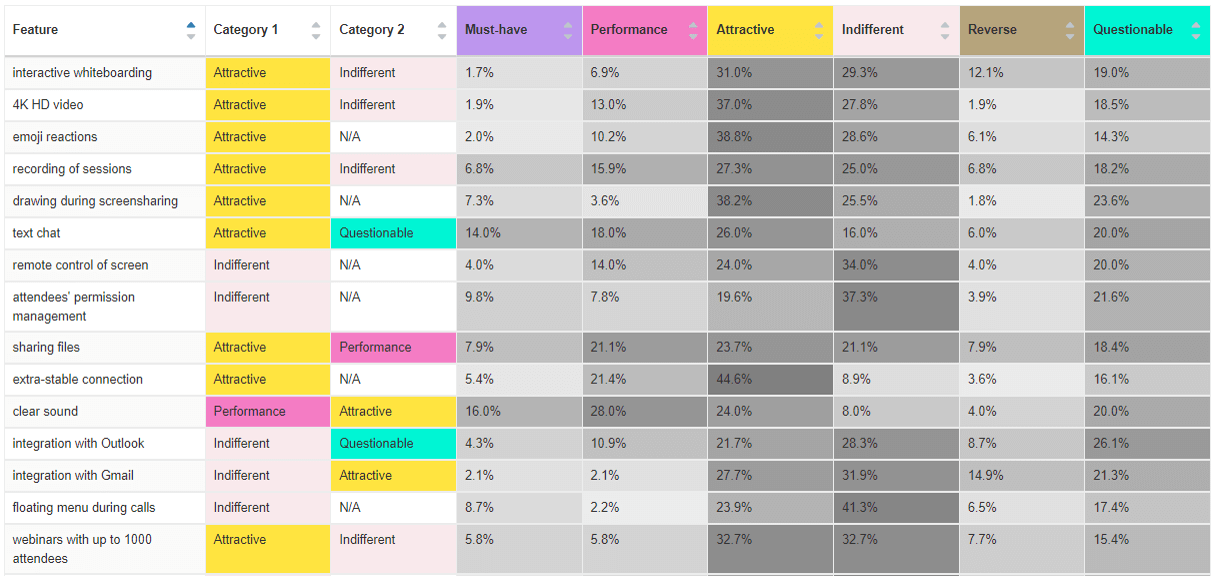
- Conjointly automatically gives you not one, but two classifications for a feature (primary and secondary).
- Conjointly interactive reports make it easy to sort by the percentage of answers for each category. So if your results do not show any attractive features in your product (sounds sad, but it can happen), you can find the “most attractive” features by sorting your columns.
Beside this point, Kano is not about stability or large sample sizes. This model works well for small sample sizes too. Indeed when it was first applied in 1980s Japan, it was on small sample sizes.
Our own criticism of Kano: Continuous analysis
We recommend using the categorical (discrete) analysis instead of continuous because in continuous analysis, the widely used cut-offs (which are also implemented on Conjointly) are arbitrary.
Conclusion
Kano is not a bad model:
- It can be unstable in some cases, but Conjointly makes it easy to work through that.
- It is theoretically sound, but very different to the likes of conjoint and MaxDiff because it mixes in qualitative assessment of features, rather than relying on a sledgehammer unidimensional scale.
Please feel free to book a call with us if you want to talk more about Kano pros and cons.