
Discover how conversational surveys unlock rich, detailed responses and give you the depth you need without endless follow-up interviews.
Guest author

Nikki Anderson, founder of User Research Strategist, helps user researchers become strategic decision-makers through her Substack, podcast, and speaking engagements. Known for transparency and actionable insights, she’s shaping the future of research while chasing waves and geeking out over Pokémon.
Open-ended survey questions can be a frustratingly huge waste of time. You write a great question. You launch the survey. You pray for depth. Instead, you get:
- “No.”
- “N/A.”
- “Nothing really.” Or the worst: “fhriuasfgerbwjh.”
Now you’re stuck. Either you run interviews to get real answers or you present shallow data that even your stakeholders can see is garbage.
We’ve all been there. It’s why researchers quietly hate surveys even while we keep running them because the scale is too useful to give up, but the depth just isn’t there.
So when I first heard about conversational surveys, I thought, cool, someone put a chatbot on top of a survey. That’ll solve everything. Not.
After trying it on Conjointly, I realized it’s about scaling good conversations without needing to run a hundred interviews yourself. Conversational surveys are amazing for mixed methods research, adding in extra layers of depth and understanding.
You get:
- Follow-up questions built in
- Response validation that filters out nonsense
- A chat-like experience that feels natural to participants and produces richer responses for you
No, it won’t replace an expert researcher, but it will make your surveys actually useful again and save you time you’d otherwise waste chasing participants down for more detail.
In this article, I’ll show you:
- When conversational surveys are useful
- How to set one up on Conjointly in 20 minutes with examples you can swipe
- A dead-simple experiment you can run today to test adding this method to your toolkit
If you’re tired of surveys that just create more work, keep reading.
How to Actually Use Conjointly’s Conversational Survey Tool
When I first tested Conjointly’s conversational survey tool, I wasn’t just curious about how it worked, I wanted to find out where it fit into a real UXR workflow. Could I use it to get actual stories, uncover friction points, or surface unmet needs? Could it scale the types of conversations I usually only get in interviews?
What follows is a method that’s worked well in my own testing. It’s based on a real study I ran with participants about budgeting habits, what tools they use, what makes them quit, and what keeps them engaged. Some of the setup (especially around how I use probes) differs slightly from how Conjointly originally suggested using the tool, but it came out really well, and was incredibly fun to play around with.
You’ll find every step here broken down: what I did, how I set it up, and what you can swipe to try in your own work.
What Makes Conjointly Worth Using
Plenty of tools claim to do “conversational” research. Conjointly actually delivers something usable for UXRs. A few things that stand out:
- Probing that’s actually smart. You can pre-write follow-up questions that trigger based on how short, vague, or incomplete someone’s answer is. This isn’t just “Tell me more” spammed to every participant.
- Built-in validation. You can define what counts as a “good enough” response. The survey won’t let someone breeze past a question with “idk” or “nothing.”
- Structured like a conversation. The interface is chat-style. That might sound cosmetic, but people do tend to write more naturally and with more context when it feels like a dialogue.
- Synthesis that doesn’t require hours of tagging. Responses feed straight into Conjointly’s analytics. You can see summaries, themes, and raw text in one place.
You’ll walk away with a working survey, designed to uncover real insight, and a way to judge whether the data you get is worth using this method again.
Step 1: Draft 3 Open-Ended Questions With Purpose
The effectiveness of a conversational survey starts here. The biggest mistake I see (and have made myself) is assuming a good topic equals a good question. In practice, vague questions get vague answers, even in a conversation-style format.
Through running my own study on budgeting behaviour using Conjointly, I found that the questions that worked best were:
- Tied to specific experiences, not opinions
- Easy to answer without context
- Written in plain, natural language
Before I wrote anything, I used this framework to shape each question (I also use this for usability testing and generative interviews!):
| Research goal | Question type | Prompt |
|---|---|---|
| Explore current behaviour | Process | “Walk me through how you usually [do X]” |
| Uncover past experience | Recall | “Tell me about the last time you [did X]” |
| Surface barriers or annoyances | Friction |
Here’s what I actually used in my Conjointly setup for a short study on budgeting tools:
- “Tell me about the last time you tried to manage your personal budget.”
- “What tool, method, or app did you use for that?”
- “What worked well for you?”
- “What frustrated you or didn’t work as expected?”
- “Have you ever stopped using a budgeting app? What led you to stop?”
- “What would make you stick with one budgeting tool long-term?”
Each one was written as a standalone message block in Conjointly, which I wanted since I thought that would make the questions much easier to answer and much more effective in this kind of method.
I avoided soft starters like “How do you feel about…” or anything that pushed people into abstract reflection. I wanted to trigger memory and behaviour. And that’s what worked; I found the more grounded the prompt, the better the response.
If you’re not sure where to begin, here are a few templates I’ve reused successfully across different topics:
- “Tell me about the last time you ___.”
- “Walk me through how you typically ___.”
- “What’s the most frustrating part of ___?”
- “What usually goes wrong when you try to ___?”
- “What’s one thing you wish was different about ___?”
If you’re stuck, write your questions badly first. Then rewrite them like you’d say them out loud in a real conversation. That’s usually where the good version lives.
Here are a few more examples:
| Domain | Good question | Weak version |
|---|---|---|
| SaaS onboarding | “Tell me about the last time you got stuck while setting up a new tool.” | “How easy or difficult was onboarding?” |
| Travel | “Walk me through the last time you booked a flight online.” | “How do you feel about flight booking platforms?” |
| Finance | “What’s the most annoying part of managing your monthly budget?” | “Do you have any suggestions for improvement?” |
Write three of these before you move on. If you’re stuck, write them badly, then clean them up.
Step 2: Write Follow-Up Probes That Trigger Better Stories
Based on my experience running unmoderated research, where participants regularly give either brief or vague responses, I approached follow-ups in Conjointly with a clear strategy: write two separate probes per question from the start.
- One for when the participant’s answer is too short
- One for when the response is vague or off-topic
I made these choices because this is usually where I struggle with unmoderated testing. While this isn’t how Conjointly initially recommends setting up probes (they default to one per question), from years of working with open-ended surveys and unmoderated tests, I knew that some participants need a push to go deeper or a nudge to clarify what they meant.
In my budgeting tool study, this structure proved especially effective for moments of friction or drop-off, places where people knew something felt off but didn’t always have language for it. For example:
Main Q: “Tell me about the last time you canceled a budgeting app.”
- If short: “What pushed you to cancel it at that moment?”
- If vague: “Can you describe the last step you took before cancelling?”
This setup produced responses like:
“I was using [App], but it didn’t let me split recurring payments. I ended up getting double charged because I forgot what I’d already budgeted for. I canceled it after a few weeks of frustration.”
That gave me a feature gap, an expectation mismatch, and a moment of action, all in one response. I might have struggled to get that answer from a single follow-up like “Can you tell me more?”
When I set up follow-ups, I think in terms of what I can’t do in unmoderated research:
- I can’t ask a clarifying question live
- I can’t watch their body language to know if something’s unclear
- I can’t read tone
When I set up follow-ups, I think in terms of what I can’t do in unmoderated research:
- I can’t ask a clarifying question live
- I can’t watch their body language to know if something’s unclear
- I can’t read tone
- Short response = maybe disengaged or assuming I don’t need more
- Vague response = maybe unsure what I’m asking, or keeping it high-level
You set these up using the “Follow-up settings” within the question block. I put custom follow-ups for each of my questions. You can see the entire prompt in Conjointly below:

This approach worked especially well in:
- Exploratory questions, where people default to shallow replies
- Conceptual tasks, where expectations mattered as much as functionality
- Decision-making moments, like uninstalling an app or choosing between tools
The biggest success with this comes not just in response length, but in usability of the insights. I was able to pull quotes directly into my synthesis doc, without having to interpret what the participant meant or chase a missing “why.”
Step 3: Use Response Validation
If you’ve ever run unmoderated research, you already know the pattern: someone gives a one-word answer, skips anything they can, or drops in “idk” just to move on. You’re left with something that technically counts as a response, but doesn’t help you learn anything.
That’s why I always build response validation into my survey setup from the start. Not just to filter out junk, but to keep the overall quality of responses high enough that I can actually do something with them.
When you’re not in the room to follow up, you need to preempt the drop in effort.
For experience-based questions, like workflows, frustrations, or tool abandonment, I set a minimum word count (usually 15) and block common filler phrases. These rules reflect the thresholds I’ve seen again and again in unmoderated formats where anything less than a couple of sentences usually lacks context or specificity.
Common phrases I always block:
- “idk”
- “nothing really”
- “just annoying”
- “don’t remember”
Conjointly makes this straightforward:
- In each message block, open the “Validation Settings.”
- Set a minimum word count. I typically use 15 for anything tied to a real experience or decision
- Add disallowed phrases, like words or short responses that signal avoidance or disengagement
- Write a custom prompt that gently encourages revision
Here’s how I configured it for one of my budgeting study questions:

This approach nudges people without making them feel corrected. It’s the equivalent of a live moderator saying, “Take a second, just tell me what happened last time this came up.”
When the floor is set properly:
- Probes work more effectively (they don’t have to compensate for garbage input)
- Synthesis takes less time
- Patterns are easier to spot
- You can use more of your dataset without caveats
I’ve used this approach in concept tests, onboarding studies, preference research, and habit tracking. It holds up across formats and topics, especially when participants are tired, distracted, or unsure how much detail you want.
When there’s no moderator present, response validation is your quality control. It’s what lets you sleep at night knowing you won’t spend hours cleaning a dataset or making excuses for your insights.
If you’re relying on open-text input to inform roadmap decisions, feed into synthesis, or share with stakeholders, then a little friction up front (through validation) saves a lot of regret later. This is a crucial part of what makes conversational surveys a viable method for early exploratory interviews when speed or scale is a constraint.
Step 4: Preview the Full Survey Flow
This isn’t a “just make sure it works” step. Previewing is where you find out whether your survey actually behaves like you want it to. Whenever I build unmoderated or conversational studies, I treat previewing like user testing: I’m checking for tone mismatches, clunky transitions, and missed cues that I’d normally pick up on in a live session.
Conjointly makes it easy to preview every message block and simulate how the conversation will unfold. Use that simulation to push your setup to its edge.
What I watch for in every preview:
1. Does the tone hold up across every message?
Each question, each follow-up, and each validation message should feel like they were written by the same person. If anything feels robotic or out of sync, I rewrite it.
2. Do the probes actually help when triggered?
I test my short and vague responses here. I’ll intentionally write things like:
- “idk”
- “just annoying”
- “used it once” Then I check:
- Did the short probe fire?
- Did the vague probe make the participant feel guided, not corrected?
- Did the validation message actually motivate revision?
3. Do transitions feel smooth?
Even though Conjointly displays one question at a time, the flow still matters. If one question feels disconnected from the last, it breaks the mental model of a conversation. I read the whole thing back in sequence to see if I’d feel like continuing if I were the respondent.
In my first draft, I had a probe after the “What frustrated you?” question that read: “Please provide more detail.”
Technically fine. But when I saw it in context, right after a participant shared a semi-useful answer, it felt cold. I rewrote it to: “What were you expecting instead?”
That tiny shift changed how it felt to engage with the question. And I wouldn’t have spotted it without running through the preview and reading it like a participant would.
Here’s an example from my survey that showcases how Conjointly can help turn a flat survey question into an open-ended conversation with prompting.

A few red flags I look for:
| What I see | What I do |
|---|---|
| Repetitive or robotic probes | Rephrase to sound like a follow-up in a real interview |
| Validation message that feels punishing | Rewrite with a more constructive tone |
| Two questions back-to-back that feel disconnected | Add a brief framing line or smooth the transition |
| Participant feels “stuck” or looped | Adjust word count threshold or simplify follow-up logic |
The goal here is a smooth, self-correcting conversation, not a script. If anything in the preview feels clunky or off-brand, it’s worth fixing. You’ll thank yourself when responses come in and you don’t need to decode what someone meant.
Step 5: Send It to 5-10 People
Before launching anything at scale, I always run a small test, usually with 5 to 10 participants. This helps you check whether the method delivers. Does the survey elicit depth? Do the probes fire in the right places? Do the answers feel usable without needing interpretation?
In unmoderated research, this kind of small dry-run gives you the equivalent of a pilot except instead of refining a script, you’re refining a flow that needs to stand on its own without you in the room.
First, send the survey to:
- Colleagues in design, product, or CS
- Power users or research friends
- Anyone who can answer thoughtfully
Inside Conjointly, you get access to the full chat log for each participant such as interviewer messages, respondent replies, probes that fired, validation messages, everything. I went through every transcript like I would with moderated sessions. Here’s what I paid attention to:
1. Were responses detailed enough to be useful without follow-up?
If a response answered the “what,” “why,” and “when,” I marked it as high quality.
2. Did probes show up in the right places?
I checked if my “short” and “vague” follow-ups were triggering where expected. I also looked for cases where no probe triggered but probably should have.
3. Did anyone get stuck or bounce out?
Conjointly logs completion and drop-off. If someone bailed mid-survey, I checked where. If someone wrote “???” in a validation-required field, I rewrote the fallback prompt.
Here’s the kind of response I got after layering probes + validation:
“I used [App] for two months. It let me categorize expenses, but it didn’t connect with my bank directly. I stopped using it when I had to keep updating everything manually, it started to feel like a second job.”
That’s a real use case, a specific pain point, and a clear decision trigger. It doesn’t just say “I stopped using it” but tells me why and when.
The same question, without the method in place, I might have gotten:
“It was fine, I guess.”
What Conjointly helps surface fast
The Conjointly dashboard shows more than just responses. It gives you:
- A full turn-by-turn transcript of every conversation
- Which probes were triggered
- Which responses passed or failed validation
- Average response length and completion rate
- Quick AI summaries once you reach 10+ completes
I was already seeing themes emerge after a handful of participants. I then copied my top three responses into a doc and asked myself:
- Would I use this quote in a deck?
- Would this answer help a designer make a change?
- Would I feel confident referencing this in a synthesis?
If I got “yes” for at least two out of three, I kept going. If not, I went back and adjusted the questions, probes, or validation logic.
Step 6: Read Your Responses Like a Strategist
The whole point of using conversational surveys, at least for me, is to collect data that’s immediately usable. If I have to decode what someone meant, guess what they were reacting to, or fix the gaps with a follow-up study, then the survey didn’t do its job.
Once the responses start coming in, I shift into synthesis mode almost immediately. I’m not just reviewing for completeness. I’m asking myself, is this answer something I could drop into a strategy deck or hand to a product team tomorrow?
And with that question, I’m not looking for clarity, specificity, and emotional signal. Here’s my personal checklist. If a response hits at least two of these, I consider it strong:
- It includes a moment in time (e.g. “last month,” “after three tries,” “when I logged in”)
- It names a specific frustration, expectation, or benefit
- It shows decision-making behaviour (not just opinion)
- It reveals something that would help a teammate act (designer, PM, etc.)
What I pulled from my budgeting survey
After applying probes and validation, my responses felt more like interview transcripts than typical survey output. For example:
“I used [App] to try tracking my food delivery spending. It let me set categories, but it wouldn’t let me separate recurring subscriptions from one-offs. That threw off the totals. I gave up after it showed I had $300 left when I didn’t.”
This response hit every one of my checklist points. It gave me:
- A clear context
- A failure moment
- A trust breakdown
- A reason for churn
You can see one of the responses from my study which showcases the follow-up and deeper probing:
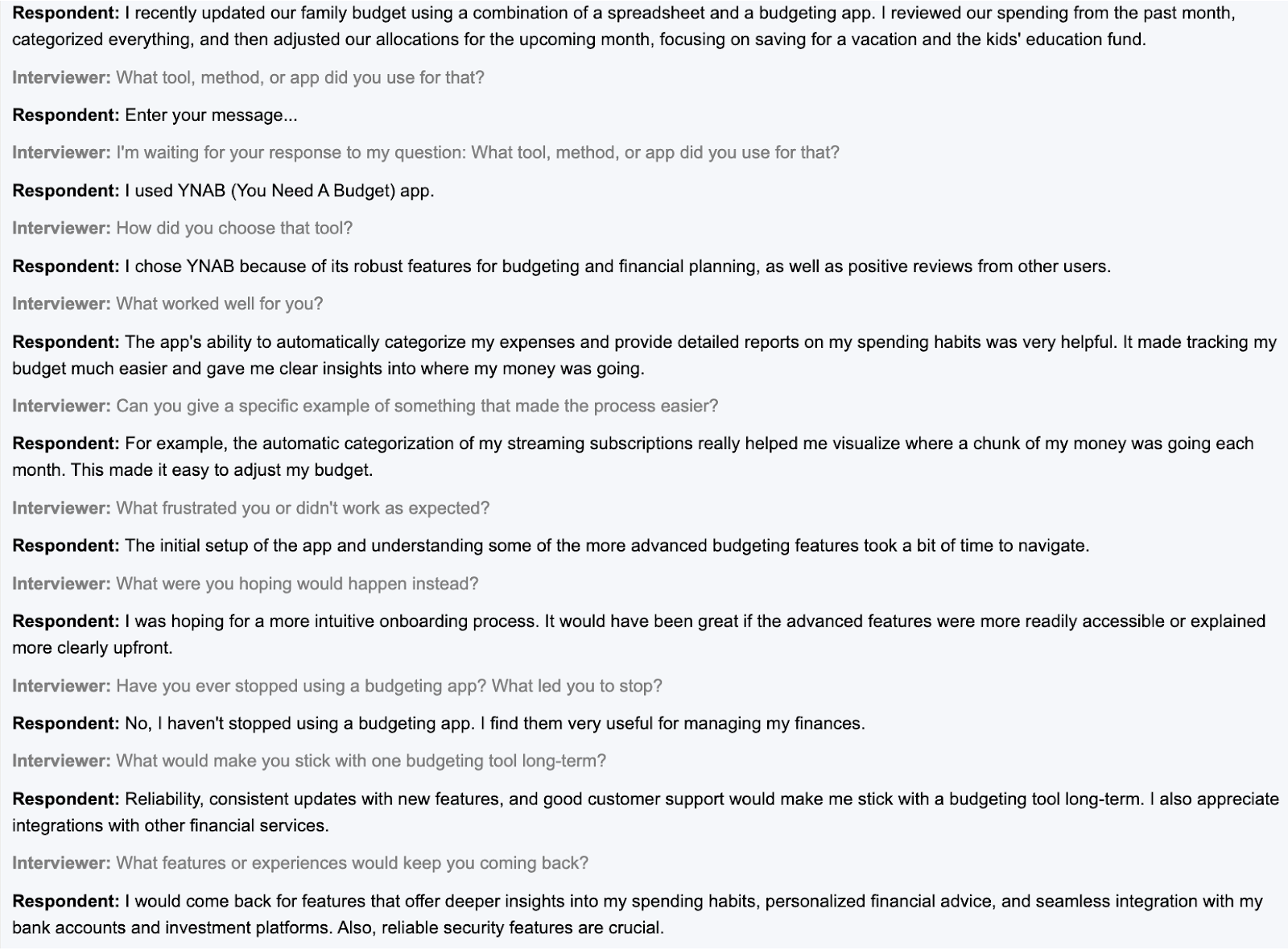
Conjointly’s dashboard made it easy to review the full conversation flow:
- I clicked into each response thread to see where probes fired
- I scanned the validation flags to see where people initially stumbled
- I used the AI summaries (available after 10+ responses) to cross-check themes I was seeing manually
- You can see some of the AI summaries from my study:

Once I had 5-6 valuable responses, I pasted them into a doc and did a basic theme mapping:
- Frustration with manual tracking
- Missed expectations around automation
- Drop-off after repeated setup friction
That question > probe > raw response > quote > theme process worked because the setup held. Here’s a small exercise I do on every conversational survey:
I hand 3 raw responses to a teammate and ask:
“Can you tell what this person was trying to do, what went wrong, and why they stopped?”
If the teammate can answer those questions without asking me for context, the method worked.
If they say, “I don’t really get what they’re talking about,” then I’ve got a signal that I need to revisit the question, the follow-up, or the validation criteria.
If your responses fall flat…
This happens. Even with a tight setup. If you’re getting vague or unusable replies:
- Revisit your main question wording—is it too abstract?
- Check if probes are too generic or aren’t firing
- Look at your validation message—does it clarify what you actually want?
And remember: this isn’t failure, it’s just a signal. One of the best things about Conjointly is how fast you can iterate. You can duplicate a question, test a variation, and compare performance side by side within the same flow.
Step 7: Judge the Tool Like a Researcher
Once I’ve tested the method and reviewed the data, I take a step back to look at the tool itself. I ask the same kinds of questions I’d use in a usability test or vendor audit to decide whether this platform can meaningfully support my research work when it counts.
The questions I ask after every pilot
Would I use this again when speed matters?
Not everything warrants a moderated study. For early signal-gathering, concept feedback, or post-launch follow-up, does this help me get useful data faster than other options?
Would I trust a teammate to run this without me?
Conjointly’s UI is straightforward enough that I could hand it to a PM or designer with a few setup tips. That’s a huge win in environments where research is spread thin.
Does this replace something that usually drains my time?
For me, that’s follow-up interviews when surveys fall flat, and long sessions spent cleaning junk responses. This tool cuts out both if the setup is strong.
Would I recommend this to a client or a team I don’t personally oversee?
That’s the bar. If I’d feel comfortable recommending it to someone I’m not directly supporting, it means I trust the results enough to stand on their own.
Where Conjointly (and conversation surveys) fit in my toolkit
Conversational surveys aren’t a replacement for in-depth generative work or rigorous testing of prototypes, but that’s not the point. For me, Conjointly’s conversational surveys fill a specific gap:
- When I need stories, but can’t run interviews
- When I need patterned friction, but don’t have time to recruit
- When I need better open-ended survey data, without spending days cleaning
It lives between moderated qual and traditional surveys. And when configured with layered prompts and validation, it does a better job than either at producing quick-turn, usable insight.
Don’t Ditch Surveys, Fix Them
Not every project can afford weeks of moderated sessions, but shallow open-text boxes don’t get you anywhere, either. Somewhere in between is a method that gives you the reach of a survey with the depth of a real conversation, if you set it up right.
That’s where conversational surveys come in. And Conjointly makes them workable, even if you’re low on time, budget, or headcount. It won’t replace your skill. But it will help you scale it without sacrificing quality.
If you’ve ever said:
- “We don’t have time for full interviews right now.”
- “I need more than a score, but I can’t wait three weeks.”
- “I just want useful answers from people who don’t ghost the question.”
This is the tool I’d recommend.
Your 20-Minute Test Drive
You don’t need a big budget or team buy-in. You don’t even need a research question you’re 100% sure about. You just need 20 minutes and a few open-ended prompts you’ve probably used before.
Here’s your challenge:
1. Sign up for a free Conjointly account
You’ll land directly in the survey builder, no credit card required.
2. Draft 3 open-ended questions
Use the templates from earlier:
- “Tell me about the last time you…”
- “What usually goes wrong when you try to…”
- “What’s one thing you wish was different about…”
3. Add 1-2 follow-up probes per question
Start with the defaults or write your own for vague or brief responses.
4. Turn on response validation
Set your thresholds: minimum word counts, banned phrases, or both.
5. Preview the full flow
Read it like a participant. Make sure it holds up.
6. Send it to 5 people
Friends, colleagues, past testers or anyone who’ll answer honestly.
7. Open the dashboard and review the data
Check the transcripts, the probes, the themes. Ask: Would I use this in a deck?
Run the experiment, one that could save you hours of cleanup, and give you better data than half your open-ended surveys ever have.
If it doesn’t work, you’re out 20 minutes.
If it does, you’ve added a practical, scalable method to your research toolkit.
Engage your consumers with interactive chat surveys

